Javascript SpeechToText

Speech To Text (STT) in Javascript is cool. There’s actually an API for it. After playing around with it for a while, I recognized its shortcomings. It doesn’t work in Safari and it doesn’t exist in Firefox. Time to build my own version that runs in all browsers.
Web applications can now use speech recognition, thanks to online services and APIs offered by Google and Apple. However, using these services means whatever you say is sent to their servers—something that makes many developers pause, and perhaps that’s why Mozilla doesn’t provide a similar API. Apple’s speech recognition service isn’t particularly reliable either, but that’s not surprising, as many advanced APIs struggle to work properly with Safari. So, while there is a speech recognition API for advanced HTML/JavaScript environments, it primarily functions well with Google Chrome, making it somewhat limiting.
The concept of speech recognition in web applications is fantastic—it allows developers to analyze spoken words and trigger events or actions based on recognized commands, like saying “submit data” to activate a form submission. Although mobile devices often come with built-in transcription services, they don’t interface with JavaScript, which limits their usefulness for web developers.
I decided to use Chrome’s Speech-to-Text API for a Progressive Web App (PWA) that would allow me to interact with my own AI system, “TinBrain,” which runs on one of my servers. Everything was working smoothly until I proudly demonstrated it to an Apple user—who couldn’t get voice recognition to work at all. That was disappointing. I needed my own speech recognition system, one that would work across devices and browsers.
And – before you ask: Yes. I know there are “in browser” speech to text modules. But you can only use tiny models, they are slow and the quality is .. well .. not comparable to what you can achieve with whisper – even if we’re only using the base.en package.
Challenge accepted.
First, the good news: I got it working. No weird libraries required. With decent network speed, the transcription time is roughly half of real time, meaning you’ll receive the transcribed text in about half the time it took to record it.
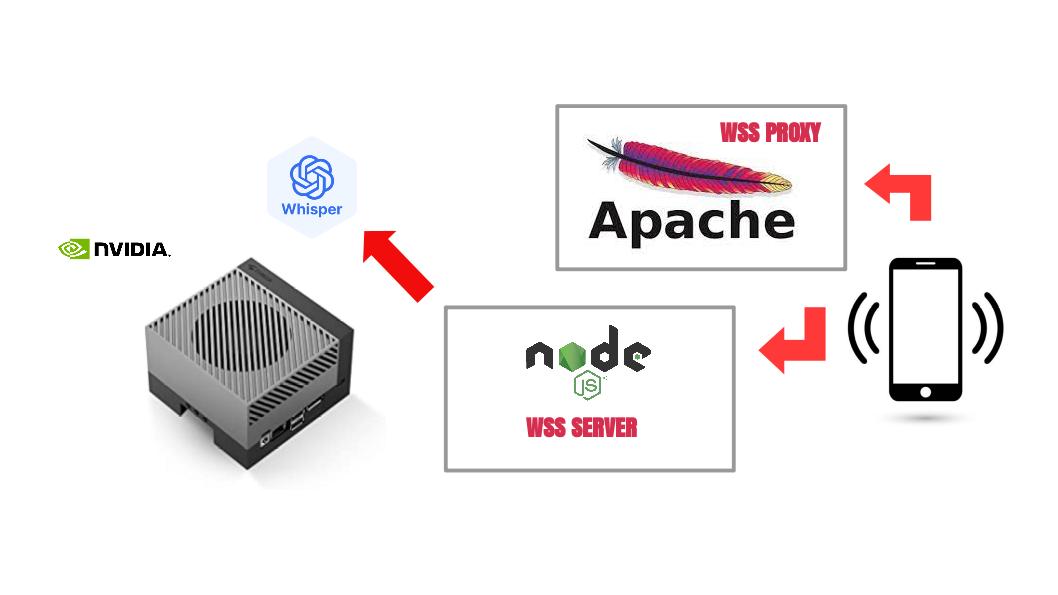
However, getting it to work was far more difficult than I anticipated. Let’s start with the back end: it runs whisper-cpp (based on OpenAI’s transcription model) on my NVIDIA Jetson AGX Orin. The developer did a fantastic job. On the console, the transcription time is about 10% of real time, meaning it can transcribe 10 seconds of audio in just 1 second. But getting Whisper compiled and running on this proprietary NVIDIA hardware was a journey of its own. Wrestling with all the necessary libraries and tools took me an entire day just to get it working properly.
Whisper itself is a command-line application. Its included server module doesn’t support WebSockets (as far as I know), so I built a Node.js server around it. That part was relatively straightforward. The bigger challenge came on the client side. Whisper.cpp requires the PCM audio to be in 16-bit, 16kHz WAV format—unfortunately, this is not the format provided by the getUserMedia API in browsers.
I didn’t want to add extra steps like running ffmpeg to convert the audio, because that would add a few more seconds to the response time. Plus, the less audio data sent across the net to the WebSocket server, the better. Also – I wanted the data to be sent chunked – streamed – while the user is still speaking.
This all had to be done client-side using JavaScript.
The process is as follows:
GetUserMedia → javascript → audioWorklet → javascript -> proxy -> node.js -> whisper.cpp
After we have permission to get the microphone, the wss connection is opened and once established, we start the usual audio capture (xx.getTracks, AudioContext), but we also add a worklet into the chain. The worklet gets the input data, calculates an average volume (so we know when to stop our recording) and converts the data to Uint16 values. The newly generated Uint16Array chunk of PCM data is then passed back to the “normal” Javascript space, where it is re-sampled from whatever sampling rate the browser presented to 16Khz. The chunk is now ready to be sent to the remote server.
The resampling was a bit of a challenge. We don’t have a lot of time to do it (it’s being done during the recording for every chunk) so I used a quick linear interpolation to get it done. But it didn’t work well. There was too much noise in the converted signal and it took me half a day to figure it out. The chunks are not necessarily aligned with the correct boundaries for resampling, so I had to take this into consideration. Once re-programmed, the resampler worked great.
After we detect a moment of silence, we send a message to remote indicating that we’re done. We can now wait for the answer. This was a bit tricky to as I needed an event to make the final callback. But wait – the event actually happens somewhere completely else. How to you observe something happening somewhere without weird workarounds like “setTimeout” ? DOM to the rescue. Just set an “onChange” event handler on a DOM element (like an text input) and trigger the event from wherever you want. I love this kind of queer thinking.
So – our data has safely been delivered to the remote node server. Just remember – we’re sending Uint16Array chunks of data but websockets flatten everything to Uint8Arrays. So there is a necessary conversion before you push the individual chunks into a buffer. And as soon as the end of audio message arrives, we are ready to assemble our chunks into a WAVE file. No need for conversion, everything is already formatted to suit the whisper.cpp process. Just create a temporary file, spawnSync the transcription process, delete the temporary file and send a message with the transcribed text back through the websocket.
If you expect multiple users on your node-server, you have to account for that of course.
Where’s the sauce? Excuse me .. source? I am cleaning it up as we speak. In the meantime, feel free to drop me a note if you have questions.
Hasta La Vista ..
Michaela
UPDATE: The first iteration of my TTS opened the websocket connection first and then started the microphone capture. That worked well, but I wanted a system that allows for continuous speech. That required some innovative thinking, because we don’t want to open a websocket if we don’t have any data to send. And when your browser is listening for continuous speech, most of the time, there will be nothing to transcribe. So, I re-worked the code to open the websocket AFTER some audio has been recognized. That of course has it’s own challenges because it takes a while for the websocket connection to be ready (especially on mobile networks) and we are already capturing audio. I developed a buffer system that captures the audio chunks while the network is being established and have it do some FIFO stuff while the audio data capturing is continuing with an open network connection. The buffer will be completely drained after the audio recording has stopped and only when the buffer is empty, we close the websocket connection. Took a while to figure out, but works nicely.
Michaela Merz is an entrepreneur and first generation hacker. Her career started even before the Internet was available. She invented and developed a number of technologies now considered to be standard in modern web-environments. She is a software engineer, a Wilderness Rescue volunteer, an Advanced Emergency Medical Technician, a FAA Part 61 (PPL , IFR) , Part 107 certified UAS pilot and a licensed ham . More about Michaela ..